A writeup for one of my recent mini projects: https://github.com/trungams/http-server
Recently, I was given a small challenge and a few days to spend. I had to create a minimal HTTP server in C++ without the help of any third-party framework. I was of course allowed to use the socket library that comes with Linux, but that was all. This was a fun project for me to work on, and I actually learned quite a few things along the way, so I decided to write up my progress in those few days. If you are reading this hoping to learn how HTTP servers work and want to implement one yourself, I hope my blog post can be a good reference for you.
As I don’t want to confuse people about the design choices of my program, I’ll give some concrete requirements about this HTTP server. These are the things that I looked to implement when I started the project:
- Programming language: C++.
- The server should be able to parse HTTP requests and send back replies.
- The server can handle 10,000 concurrent connections (C10k problem).
- It can handle 100,000 requests per second.
- As mentioned above, No third-party framework should be involved. I have to build from the transport layer.
A little background first, I have done some basic socket programming before, but most of them were in Python, where a lot of the tedious tasks are already taken care of by the language. I also did not care much about performance (i.e concurrent connections, throughput) either, since those projects did not heavily depend much on the network part. I have some other experience that could be helpful for this project. But basically, my knowledge is all scattered, and I need to glue them together to produce a complete result.
I will not give too much code in this blog post, as I have already published the source code of my HTTP server on Github so you have something to follow along with the blog. Of course, this thing is far away from being a powerful web servers with many features supported like Nginx, but I’ll leave that as a project for my future self :)
Another heads-up, some annotations in the diagrams I’m using below are hand-written by me, simply because I’m really enjoying drawing stuff with my new Wacom Tablet. So please bear with me until I get better!
Aight, let’s go into it.
Table of contents
- Socket programming
- HTTP messages
- Handling concurrent connections
- Speeding up request processing
- Benchmarking the server
Socket programming basics
HTTP communication usually takes place over TCP. A typical HTTP session often consists of three steps: The client and server establish a TCP connection stream, the client sends HTTP request over TCP connection, and then the server processes that request and sends back a reply. The second and third step can be repeated any number of times, until both client and server decide to close the underlying TCP connection. To put it in a simple diagram, this is how the process looks like in the perspective of TCP.
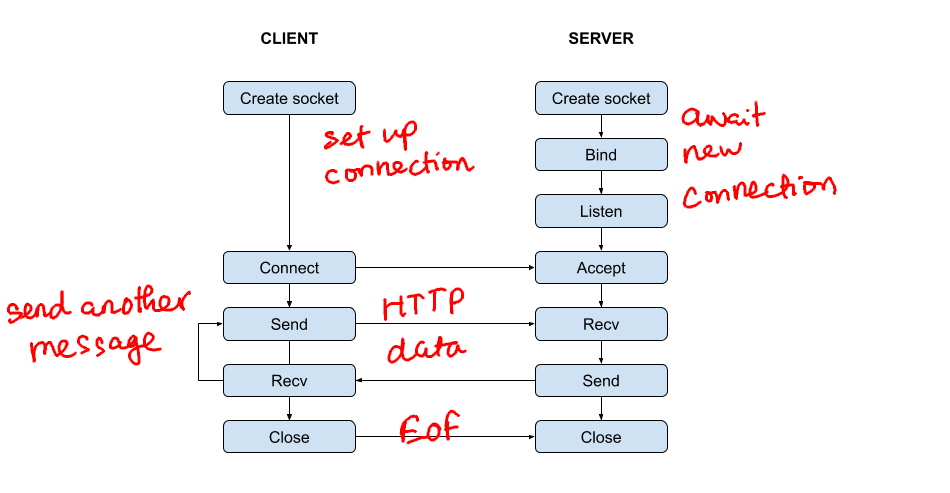
As a server, these are the main steps that we need to take care of:
- Create a socket and listen for new connections.
- Accept incoming client connections.
- Receive messages, process them and sends some responses to the client. This is where HTTP message exchange happens.
- When one party wants to close the connection, it will do that by sending an EOF character and closing the socket file descriptor.
Since there is no standard library in C++ for socket programming, I had to rely on the POSIX socket API. It is simple and does the job, as we only need to carry out the above steps. The only difference I made is in the third step, where I use C++ classes to manage HTTP messages. If you have done socket programming in C, then this is almost the same thing. Otherwise, Beej’s Guide to Network Programming might be a good place to start.
HTTP messages
HTTP is the most common application layer protocol that serves as the basis for many communications over the web. Personally, I browse Internet everyday, and I have built some small websites myself. Using popular web frameworks like Flask, Django, etc, it takes a few lines of code to spin up a decent-looking website within a few minutes. However, I never looked into how the protocol works in details until now, and I need to learn them for this project. One of the resources that I often go to for web stuff is the MDN web docs by Mozilla, but the best documentation should be the RFCs, because it is the place where the standard HTTP protocol is actually defined. To learn more about HTTP/1.1 for example, one would refer to RFC 7230-7239.
So, what is an HTTP message? In a client-server setting, HTTP messages are the requests and responses objects exchanged between the two parties. An HTTP client sends a HTTP request to an HTTP server, and the server will reply with an HTTP response. The messages must follow some format specified in the RFCs. For the small scope of my project, I picked out the most basic components to implement in my program. In short, an HTTP message should consist of:
- A start line: For an HTTP request, this line includes an HTTP method (GET, POST, HEAD, etc), a request target (URI), and a string that indicates the HTTP version (e.g HTTP/1.1). For an HTTP response, the start line (or status line) will have the HTTP version that the server used, a status code, an optionally, a message describing the status code. The start line of a message should be terminated by a CRLF character.
- Header fields: A list of key - value pairs that appear right after the start line and contain metadata about the HTTP connection and message. Each field should be on a single line and have the format
field-name: field-value - Message body: An optional sequence of bytes. The message body is often present in response messages from the server, and sometimes in requests sent by the client, depending on the HTTP method. An HTTP message body can have any format, as long as both client and server have no issue understanding it.
Some examples of HTTP messages:
HTTP request
GET /hello.html HTTP/1.1
Host: 0.0.0.0
Accept-Language: en, vi
HTTP response
HTTP/1.1 200 OK
Server: Hello
Content-Length: 13
Content-Type: text/plain
Hello, world
The classes that represent HTTP messages in my program looks as follows:
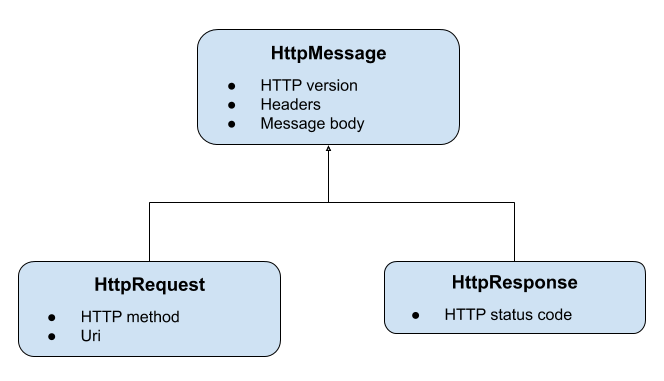
I made some heavy assumptions about the messages my server is going to receive. I assume that all requests will follow the same correct format and reject the ones that are malformed. This decision will make message parsing easier for me, as there are only a few syntax rules I need to enforce. I can then focus on the parts that I care more about in this project. If you want to have an efficient HTTP request parser, consider creating a state machine like this one.
Handling concurrent connections
The recv() and write() system calls would block by default, unless the file descriptor is set to be non-blocking. Busy waiting is fine as long as there is at most one communication stream happening at a time. That is, no two clients will attempt to connect to our server and start sending requests at the same time. If there is one client, then the sequence of actions is exactly the same as we have seen above. The server would wait for a request from the client, read the full request, return a response via the client socket, and repeat. However, when there is more than one client, just a single recv() or write() call could block the whole program anytime, causing all the operations to stop until the call returns. This is obviously very bad for a web server application, where the ability to handle communications in parallel is expected. Fortunately for us, there are some ways we can go about it.
The first approach is quite intuitive. We create a new thread for each client connection: read/write calls are free to block since it will not affect other clients. This approach is good if we have a few clients, and synchronization is not a huge concern (the state of one thread does not break other running threads). However, to scale up to 10,000 threads, one would have to be extremely careful about memory usage. Suppose that each new thread is given a 1MB stack, then 1024 threads already take up 1GB in memory. One can try to minimize the stack size so more threads can be spawned, but that will also impose a much stricter limit on the capacity of the threads.
This leads us to the second approach, that is to set the sockets to non-blocking mode (or use asynchronous I/O), and then we’ll be able to handle multiple clients in a single thread. This seems to be more memory-friendly than the other approach, so I decided to go with this one. To deal with non-blocking I/O, I used epoll. This helps me detect which file descriptor is available to perform a read or write on. I was also able to store data relevant to the read/write operations with the epoll_event struct provided. After implementing the epoll logic, my program is ready to accept and process requests from multiple clients at the same time.
Note: Handling multiple concurrent connections is actually a well-defined problem, known as the C10K problem. You can learn more about it here.
Speeding up request processing
From the understanding above about HTTP session and handling concurrent connections, I have somewhat formed a pattern for the HTTP server, which can be summarized by the following figure:
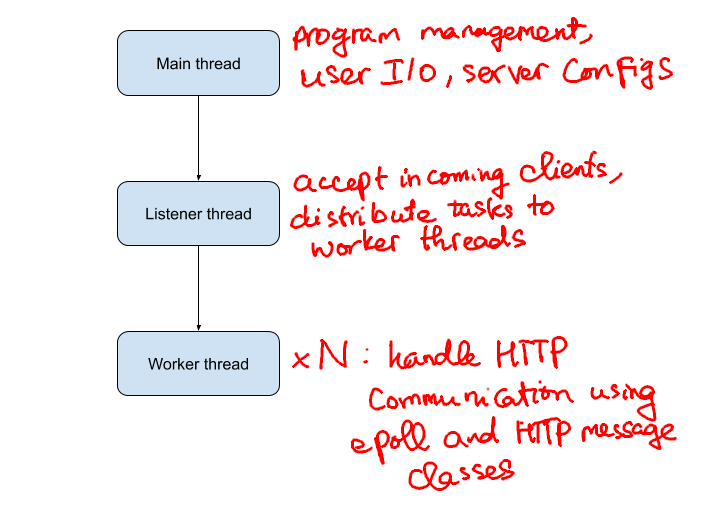
The image should be self-explanatory. But to summarize, there is a main thread responsible for setting up the server, adding URI handler, and awaits some user input to carry out some simple commands. A listener thread runs as long as the server is active, whose duty is to listen on a non-blocking socket for new connection requests from client, create a client socket and forward the client to worker threads. The worker threads do the most significant work of sending/receiving data via TCP sockets, translating those raw bytes to more meaningful HTTP messages and process them. What’s worth-noting is that there is a variable N that indicates the number of worker threads that we are going to use. Why is this number important? Based on the tasks assigned to each type of thread, we can easily see that worker threads have the most heavy workload, but because there are multiple clients, we can actually split them into parallel jobs and finish them in different threads. This is surely a promising approach, and I did some simple test runs to check my hypothesis. With a single worker thread, my server could handle about 40k requests per second, with two worker threads, that number is doubled. So it looks like we’re heading in the right direction.
After testing with different configurations, I concluded 5 worker threads would yield the best result on my machine. Now we’re ready for benchmarking.
Benchmarking the server
At this point in the project, I did not have much time left, and so I googled for the most simple web server benchmarking tool. I ended up with a tool called wrk. I carried out two tests, one for server speed, and the other one for concurrency. The clients will request for the address /, to which the server will reply with a simple HTTP status 200 and the message Hello, world!
1 minute test, 500 active clients
$ ./wrk -t10 -c500 -d60s http://0.0.0.0:8080/
Running 1m test @ http://0.0.0.0:8080/
10 threads and 500 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 5.01ms 1.31ms 57.86ms 86.35%
Req/Sec 9.94k 0.99k 36.28k 76.69%
5933266 requests in 1.00m, 441.36MB read
Requests/sec: 98760.82
Transfer/sec: 7.35MB
1 minute test, 10000 active clients
$ ./wrk -t10 -c10000 -d60s http://0.0.0.0:8080/
Running 1m test @ http://0.0.0.0:8080/
10 threads and 10000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 111.78ms 21.38ms 403.80ms 76.79%
Req/Sec 8.73k 1.42k 18.77k 75.62%
5174508 requests in 1.00m, 384.91MB read
Requests/sec: 86123.84
Transfer/sec: 6.41MB
The results look good. The HTTP server can stand still with 10,000 connected clients, and the requests per second is off by 1 thousand something in the best case. This suggests some improvements and optimizations needed in order to well surpass the 100,000 rps mark. I can immediately think of changing the HTTP request parser from a string stream based to a state machine. There are of course, so many other ways to speed up this HTTP server as well, but for now I’ll settle with this.